
DeepSeek-V3 moe nedir?
DeepSeek-V3, yapay zeka ve doğal dil işleme (NLP) alanında öne çıkan bir açık kaynaklı dil modelidir. Büyük dil modelleri (LLM) arasında dikkat çeken bu model, metin anlama, üretme ve diğer birçok dil işleme görevinde yüksek performans sergileyerek, kullanıcılara çeşitli uygulamalar için güçlü bir araç sunmaktadır. DeepSeek-V3, geniş veri kümeleri üzerinde eğitilmiş olup, dilin inceliklerini anlamada ve doğru, bağlama uygun metinler üretmede son derece etkili sonuçlar vermektedir. Bu özellikleriyle, hem araştırmacılar hem de uygulama geliştiricileri için önemli bir kaynak teşkil etmektedir.
DeepSeek-V3 MoE Modeli: Yalnızca 2 Ayda Eğitildi
DeepSeek, DeepSeek-V3 Mixture-of-Experts (MoE) adlı dil modelini sadece iki ayda eğiterek büyük bir adım attı. 2.048 adet Nvidia H800 GPU ile donatılmış bir küme kullanarak 671 milyar parametre içeren bu modeli eğitmek, toplamda 2,8 milyon GPU saati anlamına geliyor. Buna karşılık, Meta, 405 milyar parametreli Llama 3 modelini eğitmek için 16.384 H100 GPU kullanarak 11 kat daha fazla işlem gücü (30,8 milyon GPU saati) harcadı.
Optimizasyonlarla Gelen Verimlilik
DeepSeek, bu olağanüstü başarıyı, gelişmiş optimizasyon teknikleri sayesinde gerçekleştirdi. Şirket, iletişim hattı algoritmalarını geliştirdi, optimize edilmiş iletişim çerçeveleri ve FP8 düşük hassasiyetli hesaplama kullanarak, büyük modellerin gerektirdiği hesaplama ve bellek taleplerini önemli ölçüde azalttı.
Bir diğer önemli gelişme, DeepSeek'in DualPipe algoritması ile, özellikle MoE mimarisi için kritik olan uzman paralelliği gereksinimlerini iyileştirmesi oldu. Bu optimizasyon, eğitim sırasında küme içindeki iletişim yükünü neredeyse sıfıra indirerek 14,8 trilyon jeton (token) işlenmesine olanak sağladı.
Daha Az Trafik, Daha Yüksek Verimlilik
DeepSeek, DualPipe algoritmasını kullanarak, eğitim sırasında iletişim verimliliğini arttırırken, her bir jetonu yalnızca maksimum dört düğüm ile sınırlayarak trafikteki aşırı yükü azalttı. Bu sayede, iletişim ve hesaplama süreçleri etkin bir şekilde örtüşerek, verimlilikte büyük bir artış sağlandı.
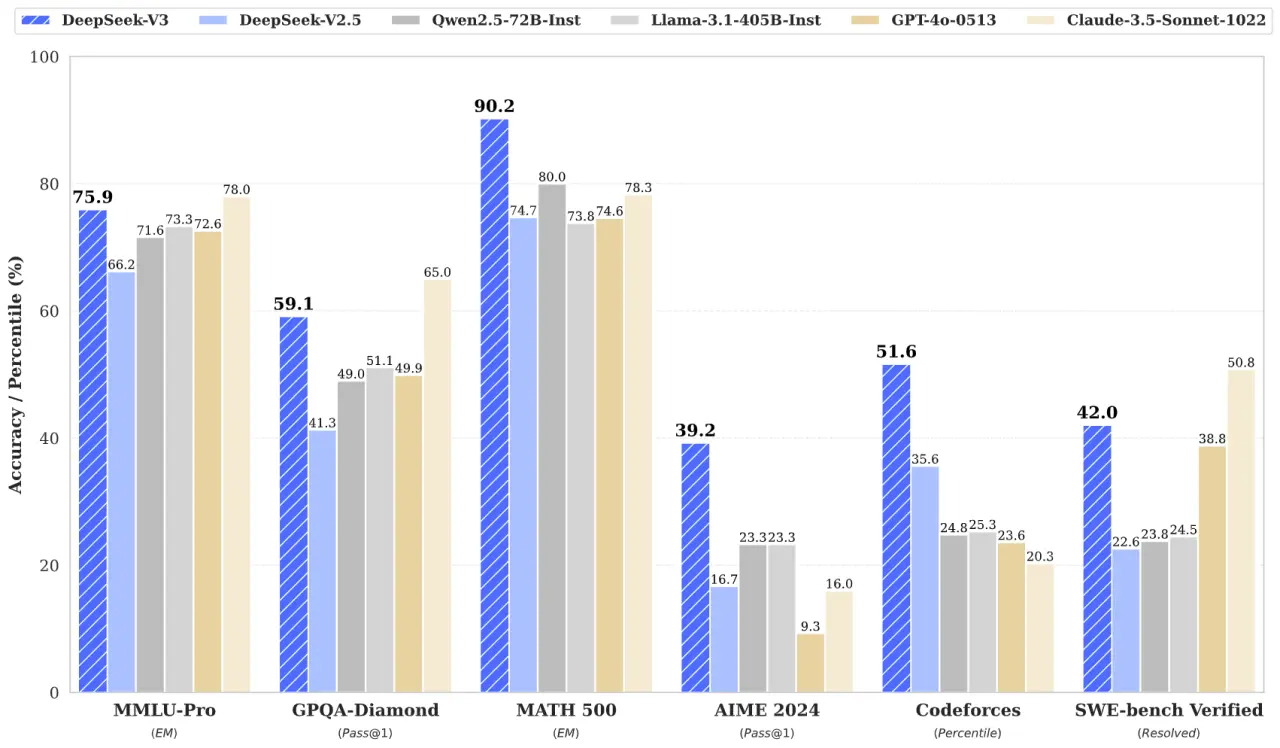
DeepSeek-V3'ün Performansı
DeepSeek, geliştirdiği DeepSeek-V3 MoE dil modelinin, sektördeki rakip modellerle karşılaştırıldığında üstün performans sergilediğini belirtiyor. Şirketin iddiasına göre, DeepSeek-V3, GPT-4x, Claude-3.5-Sonnet ve Llama-3.1 gibi popüler modellerle kıyaslanabilir veya onlardan daha iyi performans gösteriyor. Ancak bu iddiaların doğruluğu, üçüncü taraflarca yapılacak bağımsız testlerle kanıtlanması gerekiyor. Şirket, modelini ve ağırlıklarını açık kaynaklı hale getirerek, yakında karşılaştırma testlerinin yapılmasını bekliyor.
DeepSeek-V3'ün Kullanım Alanları
DeepSeek-V3, çeşitli alanlarda kullanılabilecek potansiyele sahiptir:
- Metin Üretimi: İçerik oluşturma, makale yazma, şiir yazma gibi görevlerde kullanılabilir.
- Çeviri: Diller arasında çeviri yapmak için kullanılabilir.
- Bilgi Erişimi: Soruları cevaplamak, bilgileri özetlemek gibi görevlerde kullanılabilir.
- Kod Üretimi: Yazılım geliştirme süreçlerinde kod üretmek için kullanılabilir.
- Eğitim: Öğrencilere kişiselleştirilmiş eğitim materyalleri sunmak için kullanılabilir.




















